문자열 검색이란, 전체 문자열(짚더미(HayStack)에 비유합니다)에서 원하는 문자열(바늘(Niddle)에 비유합니다)의 위치를 모두 찾는 알고리즘입니다. 문자열의 위치는 전체 문자열에서의 시작 인덱스로 나타냅니다. 가장 간단한 구현방법과, 이를 개선한 KMP 알고리즘을 알아보도록 하겠습니다.
이 포스트는 다음 책의 내용을 정리해서 Swift로 포팅한 것입니다. 원본 코드와 이미지는 모두 해당 책에서 인용한 것임을 밝힙니다.
프로그래밍 대회에서 배우는 알고리즘 문제 해결 전략
-
간단한 구현
문자열의 모든 위치에서 비교 연산을 수행해보는 방법이 있습니다.func naiveSearch(toFind str: String) -> [String.Index] { var result: [String.Index] = [] for i in 0 ..< self.count - str.count { let begin = self.index(self.startIndex, offsetBy: i) let end = self.index(begin, offsetBy: str.count) let subStr = self[begin ..< end] if subStr == str { result.append(begin) } } return result }비교를 수행하는 중간에 하나라도 실패하면 더이상 비교를 수행하지 않고 끝냅니다. 이 구현도 대부분의 경우에는 금방 불일치가 발생하기 때문에 효율적으로 동작하지만, 일부 입력에 대해 지나치게 비효율적이라는 단점이 있습니다. ex) a로만 이루어진 문자열에서 ‘aaaaaaab’ 등을 찾는 경우
이 알고리즘은 전체 문자열의 모든 위치에서 탐색을 수행하고, 매 탐색마다 최대 찾으려는 문자열 길이 만큼의 비교가 수행되므로 전체 시간 복잡도는 O(|H| * |N|)입니다.
-
KMP 알고리즘
매 위치마다 새로 탐색을 시작하는 것은 너무나 비효율적입니다. 이전 탐색의 결과를 재사용 한다면 아예 후보가 될 가능성이 없는 것들을 걸러내서 검색을 더 효율적으로 수행할 수 있을 것입니다. 이 때 필요한 정보는 두가지입니다.-
몇글자가 일치했는가?
-
일치한 글자수에 따라 건너 뛸 수 있는 글자수가 몇 개 인가?
2번 정보는 어떻게 구할 수 있을까요? 다음 그림을 보도록 합시다.
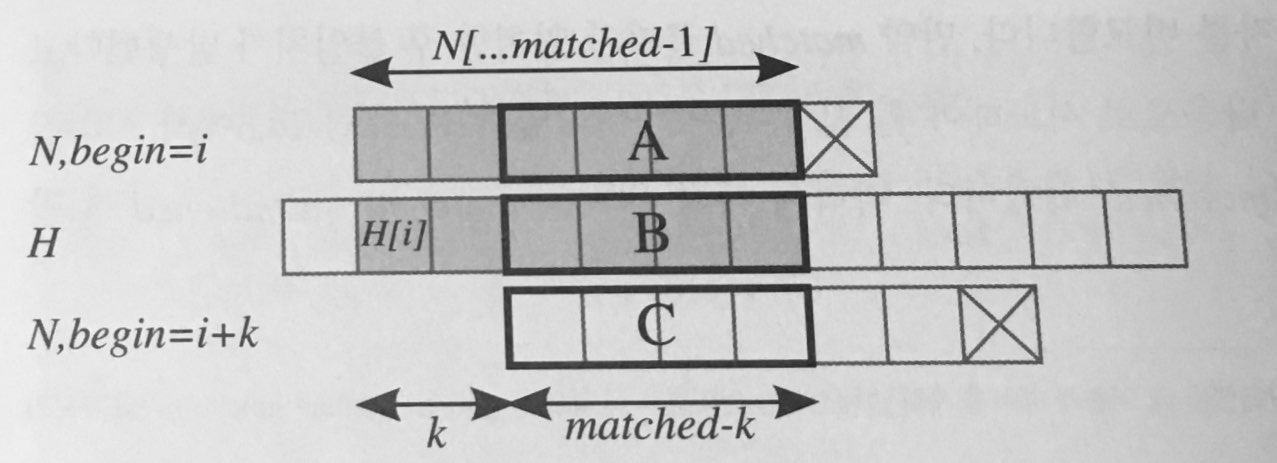
출저: 알고리즘 문제해결전략 2권 p647 그림에서 회색으로 된 부분이 일치하는 부분입니다. 따라서 일치하는 문자열 중 일부인 A와 B는 서로 같습니다. 이 때, 새로운 검색 지점이 유효할 가능성이 있기 위해서는 해당 지점에서의 문자열의 접두사가 A와 일치해야 합니다. 즉, 일치하는 문자열의 접두사이자 접미사가 되는 문자열의 길이를 알면, 다음 위치를 바로 찾아갈 수 있습니다. 이는 N을 이용해서 미리 계산해 둘 수 있습니다.
이를 구현한 코드를 보면 다음과 같습니다.
func kmpSearch(toFind str: String) -> [String.Index] { let n = self.count let m = str.count var result: [String.Index] = [] // pi[i] = N의 길이가 i인 접두사의 접두사도 되고 접미사도 되는 문자열의 최대 길이 let pi: [Int] = str.getPartialMatch() var begin = 0 var matched = 0 while begin <= n - m { let hIndex = self.index(self.startIndex, offsetBy: begin+matched) let nIndex = str.index(self.startIndex, offsetBy: matched) if matched < m, self[hIndex] == str[nIndex] { matched += 1 if matched == m { result.append(self.index(self.startIndex, offsetBy: begin)) } } else { if matched == 0 { begin += 1 } else { begin += (matched - pi[matched - 1]) // 옮긴 후에도 pi[matched-1] 만큼은 //일치함이 보장 되기 때문에 미리 옮겨준다. matched = pi[matched - 1] } } } return result }
이 함수의 시간 복잡도는 어떻게 될까요? getPartialMatch의 구현을 본 뒤에 다시 살펴보긴 해야겠지만, 자세히 보면 문자 비교가 일치하는 경우는 단 한번씩 밖에 존재하지 않는다는 것을 알 수 있습니다. 비교가 실패해도 인덱스가 증가하기 때문에, 전체 if문 수행 횟수는 O(|H|)입니다. 따라서 전체 시간 복잡도도 O(|H|)입니다. -
-
부분 일치 테이블 생성하기
getPartialMatch는 어떻게 구현을 해야할까요? 처음 문자열 탐색 구현에서 본 방법으로 접두사를 구할 수도 있습니다. 가능한 모든 답을 시도해 보는 거죠func getPartialSearchNaive() -> [Int] { let m = self.count var result = Array(repeating: 0, count: m) for begin in 0 ..< m { for i in 0 ..< m-begin { let postfixIndex = index(startIndex, offsetBy: begin+i) let prefixIndex = index(startIndex, offsetBy: begin) if self[postfixIndex] != self[prefixIndex] { break } result[begin+i] = Swift.max(result[begin+i], begin+1) } } return result }하지만 이 코드도 KMP 알고리즘을 이용해 수정해 볼 수 있습니다.
func getPartialMatch() -> [Int] { let m = self.count var result = Array(repeating: 0, count: m) var begin = 1 var matched = 0 while begin + matched < m { let postfixIndex = self.index(startIndex, offsetBy: begin+matched) let prefixIndex = self.index(startIndex, offsetBy: matched) if self[prefixIndex] == self[postfixIndex] { matched += 1 result[begin + matched - 1] = matched } else { if matched == 0 { begin += 1 } else { begin += matched - result[matched - 1] matched = result[matched - 1] } } } return result }이 구현은 KMP 알고리즘의 시간 복잡도를 그대로 따라갑니다. 따라서 O(|N|)의 시간 복잡도를 가지고, KMP 알고리즘 전체의 시간 복잡도는 O(|N|+|M|)입니다.